Hierarchical & Empirical Bayes
Topic 28 closes Track 7 by bending the tools of Topics 25–27 onto structures where group-level parameters share a common distribution and the prior itself has a prior. Eight schools as the spine example. Three full proofs — Stein's paradox via Stein's identity (featured), the partial-pooling shrinkage formula in the Normal–Normal hierarchy, and volume preservation + funnel decoupling for the non-centered reparameterization. Empirical Bayes as the boundary case. Linear mixed-effects. HMC diagnostics. The forward-map to formalml closes the track.
28.1 Three ways to pool, one dataset
Eight schools each ran a short-term coaching program for the SAT-verbal section. Each school estimates its own treatment effect with a standard error that reflects its sample size. The data, from Rubin’s 1981 analysis (RUB1981, reproduced in GEL2013 §5.5):
| School | A | B | C | D | E | F | G | H |
|---|---|---|---|---|---|---|---|---|
| (effect estimate, SAT-V points) | 28 | 8 | −3 | 7 | −1 | 1 | 18 | 12 |
| (standard error) | 15 | 10 | 16 | 11 | 9 | 11 | 10 | 18 |
The effects are plausibly between and and the standard errors are large — 28 and may just be noise around a common truth, or they may be real differences between schools. The question is how to estimate each school’s effect given all the data.
Three answers sit at the extremes and the middle.
- No pooling. Treat each school as its own problem: . Honest about between-school differences, but hostage to each . School A’s 28-point estimate carries a -point standard error — we shouldn’t read too much into it.
- Complete pooling. Treat all schools as one problem: for every , where is the precision-weighted grand mean ( here). Huge precision gain, but tosses out any real differences.
- Partial pooling. Assume the are drawn from a common distribution . Each school’s posterior mean becomes a precision-weighted compromise: with . Schools with small stay close to ; schools with large drift toward . Both the between-school variance and the group means are learned from the same data.
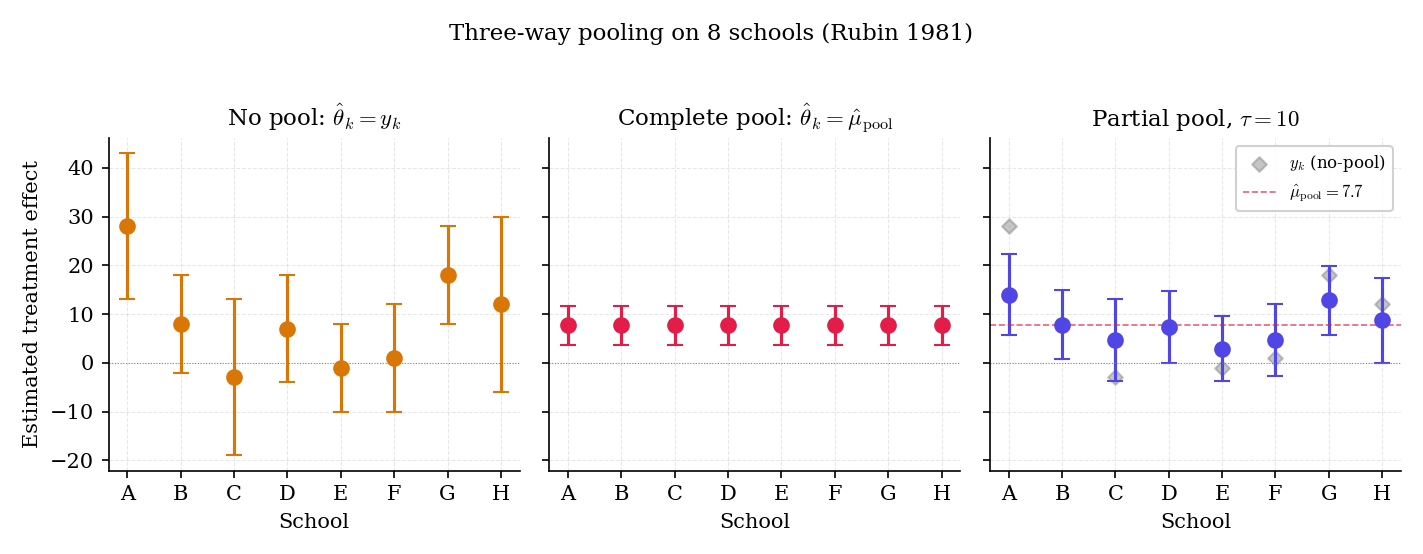
Figure 1. The three pooling regimes on 8-schools. Partial pooling is the middle panel — each school’s posterior mean is a weighted average of its raw estimate and the grand mean, with weights determined by the relative size of (noise in ) and (spread across schools).
Topic 28 is the story of partial pooling. Six intertwined threads run through the next ten sections:
- The hierarchical model as a two-level generative process (§28.2).
- Full-Bayes inference via Gibbs + HMC, with §26.8 Rem 23’s 8-schools funnel (§28.4).
- Stein’s paradox (§28.5): even when the group means are unrelated in truth, shrinkage toward any common target strictly dominates the MLE under squared-error loss in dimensions. The pedagogical summit of Track 7.
- Closed-form partial pooling in the Normal–Normal hierarchy (§28.6), with the shrinkage factor proved.
- Empirical Bayes (§28.7): and learned from the data via Type-II MLE; the 8-schools boundary case motivates full-Bayes over EB.
- Non-centered reparameterization (§28.9 Thm 7): the geometric trick that lets HMC actually mix on a hierarchy, proved via a block-triangular Jacobian.
Three sections pivot between these threads: notation (§28.3), linear mixed-effects (§28.8), and the track-closer forward-map (§28.10).
Rubin’s 1981 motivation was not primarily statistical — a research group wanted to know whether coaching helped, and a meta-analytic question followed: do we believe school A’s 28-point effect, school C’s , or some compromise between each school’s point estimate and the grand mean?
Complete pooling answers “roughly everywhere,” losing school A’s apparent success and school C’s apparent null. No pooling answers “trust each school’s sample mean,” but then school C’s with is barely different from zero, so the no-pool answer is mostly noise. Partial pooling provides the compromise. The partial-pool answer — at , consistent with GEL2013’s posterior analysis — moves school A’s estimate down toward and school C’s up toward , scaled by how informative each is individually.
Under squared-error loss, partial pooling is guaranteed to dominate at least one extreme in finite samples: it beats complete pooling when the between-school variance is real (so ) and beats no pooling when the within-school errors are large (so is non-trivial relative to ). Stein’s paradox (§28.5) sharpens this: in , shrinkage dominates the MLE uniformly in — not just for “similar” group means, but for every configuration. Topic 28’s hierarchical prior is the Bayesian reading of this dominance.
Topic 25 established conjugate priors and the posterior-as-update formalism; Topic 26 added MCMC; Topic 27 added Bayes factors and BMA. Topic 28 combines all three on the natural setting where “the prior itself has a prior” — and shows that this simple step reframes decades of frequentist results (James–Stein shrinkage, ridge regression’s bias-variance tradeoff, the Hoerl–Kennard inequality) as Bayesian inference with hyperpriors. The track closer is partial pooling.
28.2 The hierarchical model
The objects of Topic 28 come in two levels. Group-level parameters govern the distribution of the data; hyperparameters govern the distribution of the ‘s. The prior on becomes conditional on , and itself gets a prior.
A hierarchical model is a joint distribution over data , group-level parameters , and hyperparameters that factors as
Inference targets the posterior and its marginals , .
The conditional-independence structure is load-bearing: given , the ‘s are independent draws from a common distribution; given , the ‘s are independent across groups. The posterior couples the ‘s through — that’s where partial pooling comes from.
The workhorse special case. Observe sample means with known (the within-group sampling variance). Group-level prior Hyperprior . Default choices: (improper flat) and (GEL2006 default; §28.7 Rem 17 motivates).
This is the canonical 8-schools model. is the grand-mean-of-means; controls between-school spread.
Let be the count of successes in trials for group : . A natural hierarchical prior uses the Beta: Hyperparameters might themselves carry vague priors ( each, or a hyperprior on per Gelman’s reparameterization). Integrating out gives the Beta-Binomial marginal for — a compound distribution that was already in our posterior predictive toolkit (Topic 25 §25.5 Ex 2). The hierarchical model reuses it as a group-level sampling distribution.
Seventy rodent groups tested a tumor-promoting chemical; group reports tumors in rats. Complete pooling gives a single success rate (throwing out real between-group differences in baseline tumor prevalence); no pooling gives 70 separate Bernoulli estimates (ignoring that these are the same species, same chemical, similar conditions). Partial pooling with a Beta-Binomial hierarchy: individual are regularized toward an estimated with spread governed by . This is the template — 8-schools in the Gaussian family, rat-tumor in the Bernoulli family — that every hierarchical-model textbook uses to introduce partial pooling.
Group labels are exchangeable if their joint distribution is invariant under any permutation of the indices: for every permutation . Exchangeability is the Bayesian reading of “groups share a common structure but are otherwise equivalent” — de Finetti’s theorem then guarantees that an exchangeable sequence is a conditional mixture over i.i.d. sequences, so the hierarchical factorization is essentially forced by the assumption.
Exchangeability fails when some groups are known a priori to behave differently. A clinical trial with 20 standard-dose arms and 5 high-dose arms is not exchangeable across all 25 arms — dose is an informative label. The fix is to model conditional exchangeability: arms are exchangeable within a dose group, with dose-specific hyperparameters. This is the gateway to multilevel hierarchies (three, four, or more layers) — developed in §28.8 and fully at the formalml mixed-effects topic.
Frequentist mixed-effects models (§28.8, Laird–Ware 1982) use the same two-level structure but estimate by maximum likelihood or REML and treat as random-effects predictions (BLUPs). The computational machinery differs — no hyperprior, no MCMC — but the conceptual shape is identical. Topic 28 covers the Bayesian reading; the frequentist reading sits at formalml.
A hierarchical prior on within-model parameters composes cleanly with BMA across a discrete set of models. §28.10 Ex 16 treats hierarchical BMA as the natural combination: each candidate model specifies its own , and BMA weights each model’s hierarchical posterior by its marginal likelihood. This closes Topic 27 §27.10 Rem 26’s forward-promise.
28.3 Notation
Topic 28 inherits Topic 25 §25.3 verbatim (prior , posterior , marginal , likelihood , parameter , independence ). Extensions:
| Symbol | Meaning | First use |
|---|---|---|
| Number of groups | §28.1 | |
| Sample size within group | §28.1 | |
| Group- parameter (often a mean) | §28.2 Def 2 | |
| Full group-parameter vector | §28.2 Def 2 | |
| Hyperparameters shared across groups | §28.2 Def 3 | |
| Normal–Normal hyperparameters (grand mean, between-group variance) | §28.2 Def 2 | |
| Within-group observation variance (usually known) | §28.2 Def 2 | |
| Group- summary statistic (often ) | §28.2 Def 2 | |
| Shrinkage factor for group | §28.6 Thm 4 | |
| MLE, James–Stein, partial-pool estimators | §28.5–§28.6 | |
| Non-centered auxiliary: | §28.9 Thm 7 | |
| Frequentist risk under squared loss | §28.5 Thm 2 | |
| Type-II marginal likelihood | §28.7 Def 4 |
Subscripts: indexes groups; indexes observations within a group (used in §28.8 when ); indexes coordinates in in §28.5. In Stein-paradox context (§28.5), the literature-standard symbol replaces . The semantic mapping: groups of scalar Normal means a -dimensional Normal mean vector with . §28.5 Rem 10 flags this bridge explicitly before the proof.
28.4 Full-Bayes inference on
The joint posterior almost never has closed form — even for Normal–Normal, integrating against a Half-Cauchy hyperprior is intractable. Topic 26’s MCMC machinery handles this directly: Gibbs when full conditionals are conjugate (Normal–Normal is), HMC/NUTS when they aren’t (Beta-Binomial hyperpriors on typically aren’t).
For the model in Def 2 with flat prior and , the full conditionals are all standard distributions:
Gibbs sweeps through the three full-conditional updates in any order; the invariant distribution is the joint posterior .
The third conditional is already the partial-pool posterior — §28.6 will prove this closed form from first principles.
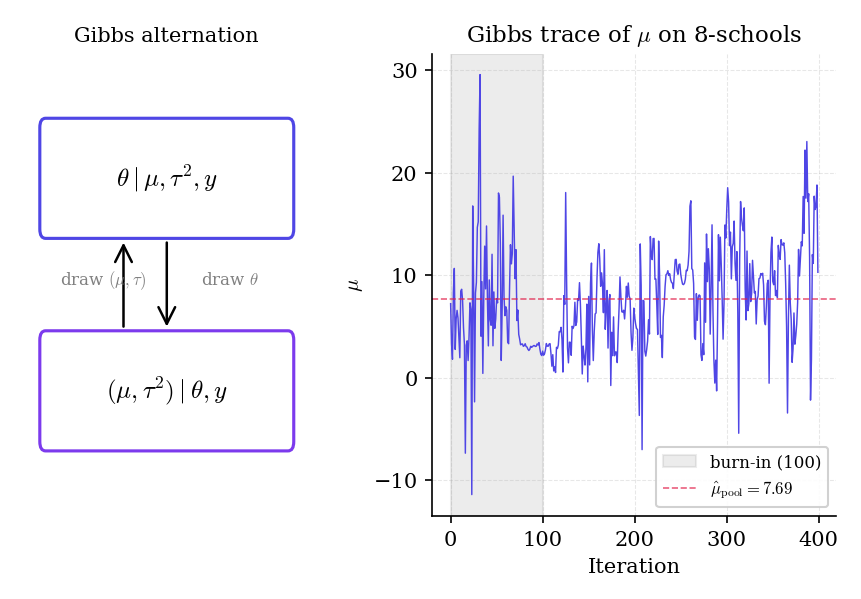
Figure 2. Block Gibbs for Normal–Normal. Left: the alternation diagram — sample given the hyperparameters, then sample the hyperparameters given . Right: 200 iterations of from an 8-schools Gibbs run. The chain mixes quickly because all full conditionals are Gaussian or inverse- — no Metropolis rejection to slow it down.
From a warm start :
- Sample : a Gaussian centered at with standard error . If , that’s .
- Sample : an inverse- whose scale tracks the spread . When the ‘s are close, gets pulled small — reinforcing further shrinkage at the next step.
- Sample each : Gaussian with mean . Schools with large see their ‘s pulled toward ; schools with small stay near .
Iterate 4000 times, discard 1000 as burn-in. The posterior of is represented by the 3000 post-burn-in draws.
Replace the inverse- prior on with the half-Cauchy on (GEL2006 default): the full conditional for is no longer standard, so Gibbs on that component fails. Option 1: Metropolis-within-Gibbs with a proposal on . Option 2 (preferred): HMC or NUTS on the joint — differentiate the log-posterior and let leapfrog integration do the mixing. §28.9 returns to this workflow with the 8-schools funnel.
The conjugacy of the Normal–Normal hierarchy is fragile: it relies on Normal observations, a Normal group-level prior, and specific forms of the hyperpriors on . Swap any of these for something non-conjugate (Student- errors, a group-specific prior that isn’t Normal, a hyperprior that breaks conjugacy) and Gibbs falls apart. §28.8’s linear mixed model extends the Normal case to include covariates; §28.9’s HMC treatment handles everything else.
In the prior, the ‘s are conditionally independent given . In the posterior, they are not: conditioning on induces correlations because is itself learned from the data. Partial pooling is literally this posterior correlation — every ‘s posterior mean depends on every other through the shared .
“Conditional” estimators of fix at some value (the MLE, the Type-II MLE, the posterior mode) and compute . “Marginal” estimators integrate out: . The two can differ substantially — especially when the -posterior has mass near the boundary (τ² small). §28.7 dissects this contrast: EB is the conditional-at-MLE estimator; full Bayes is the marginal one.
28.5 Stein’s paradox
In 1956, Charles Stein proved a theorem that upended fifty years of mathematical statistics: for a multivariate Normal mean, the sample mean — the MVUE, the MLE, the “obvious” estimator — is inadmissible in dimensions. There exist estimators (the James–Stein family) with strictly smaller risk for every true mean , not just on average.
The apparent paradox: a clinical-trial arm in Boston, a wheat yield in Iowa, and a baseball batting average — three unrelated quantities — should still be jointly shrunk toward some common point to reduce total squared-error risk. This is the theorem. The resolution is that squared-error loss is a sum across coordinates, so trading a little bias on each coordinate for a lot of variance reduction overall is a win. Topic 28 reframes this as empirical Bayes: “three unrelated quantities” are related — as observations drawn from a shared hyperprior the data has to learn.
Let with . Under squared-error loss , the MLE has risk for every . The James–Stein estimator
has strictly smaller risk:
The expectation is under , so is non-central chi-squared with degrees of freedom and non-centrality .
The Stein-paradox literature uses (or ) for the dimensionality of the Normal mean vector. Topic 28 uses throughout §§28.1–28.4 and §§28.6–28.10 for the number of hierarchical groups. The two are the same object — a -vector of Normal means is a collection of scalar group means, stacked. §28.5 switches to to match Stein/James/Efron-Morris notation; starting at §28.6 we revert to . The bridge: .
Proof 1 Proof of Thm 2 (Stein's paradox, via Stein's identity) [show]
Setting. , . Write . Under squared-error loss, the risk decomposes as
Lemma (Stein’s identity). Let and differentiable with . Then
Proof of lemma. Integration by parts against the Gaussian density , using :
with boundary terms vanishing under the integrability assumption.
Main calculation. Expand the squared norm of :
Take expectations term by term. The first term is because . The third term is , which is finite and positive for . The middle term is the work.
Write with . Conditioning on , the conditional distribution of is ; apply Stein’s identity coordinatewise:
Sum over :
Substitute into the risk expansion:
Since is non-central with , the expectation is finite and strictly positive. Hence for every . — using Stein’s identity (STE1956) and the James-Stein 1961 representation (JAM1961).
The shrinkage factor is positive when and negative otherwise — plain JS can flip the sign of , which is never the right answer. The positive-part JS estimator (EFR1973) dominates plain JS uniformly in and is the estimator used in practice.
Under the model and with known and estimated by its Type-II MLE, the posterior mean of coincides with the James-Stein estimator up to a finite-sample correction. The plug-in is , yielding shrinkage factor for large — exactly Stein’s shrinkage coefficient, with the adjustment arising from the unbiased estimation of via Stein’s identity (EFR1973).
This is the Efron–Morris rereading: Stein’s paradox is not a paradox at all but a theorem about empirical-Bayes shrinkage. The “unrelated quantities” are related by the empirical prior the data itself estimates.
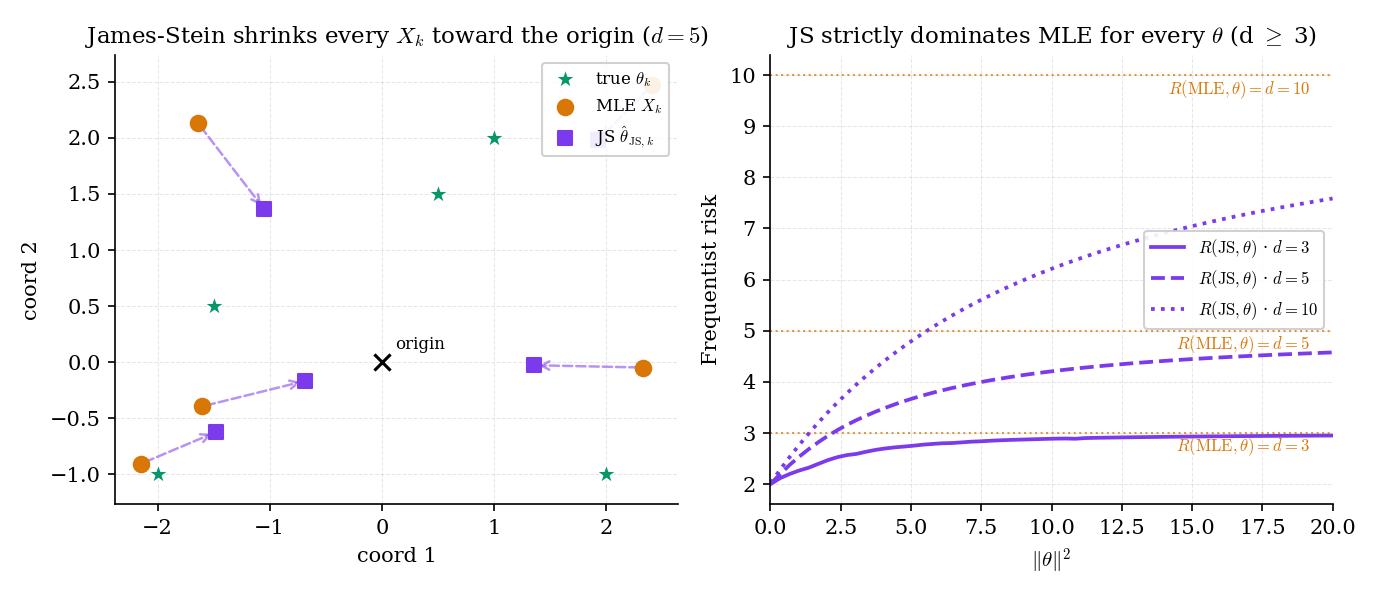
Figure 3. The Stein shock, visualized. Left: five 2D observations with JS-shrunk estimates — every arrow bends toward the origin. Right: risk curves for . The MLE sits on the flat line; JS curves dip substantially at and rise back toward as (but never reach it).
For :
- At : (central), so . Risk reduction: . JS risk: . 60% improvement over MLE.
- At (so ): is non-central ; . Risk reduction: . JS risk: . Small but positive.
Savings are largest when is near the shrinkage target (here, the origin) and shrink toward zero as grows.
The plain JS estimator can flip signs when . The positive-part correction (EFR1973) clamps the shrinkage coefficient at zero and dominates plain JS uniformly. Baranchik 1970 generalizes further: any estimator of the form with bounded between 0 and dominates the MLE in . The full Baranchik family and its Bayesian-structural interpretation (a nonparametric empirical-Bayes prior) lives at formalml.
Stein’s theorem fails for : in those dimensions the MLE is admissible under squared-error loss (Hodges–Lehmann 1951 for ; Stein 1956 for ). The proof above breaks because diverges for central — the risk-reduction term is unbounded. In , the non-centrality parameter doesn’t save us (the expectation diverges even at when ), so Stein’s construction only works when the central has finite reciprocal moment.
28.6 Partial pooling in the Normal–Normal hierarchical model
The closed-form partial-pool posterior is the single most useful calculation in hierarchical Bayes. It makes the shrinkage factor explicit, shows exactly how within-group noise trades against between-group spread , and gives us the analytical baseline every MCMC result should match in conjugate settings.
In the Normal–Normal hierarchical model (Def 2), conditional on :
where
is the shrinkage factor for group .
Interpretation: is the weight on the grand mean in the posterior mean; is the weight on the raw observation . Edge cases: forces (complete pooling, every group at the grand mean); drives (no pooling, every group at ). The posterior variance is — less than the no-pool by exactly the shrinkage factor, because borrowing strength from narrows the interval.
Proof 2 Proof of Thm 4 (partial-pooling formula) [show]
Setting. with known; hierarchical prior iid across ; condition on fixed. We derive the posterior of given .
Step 1: write densities as exponentials. The posterior is proportional to prior times likelihood:
Step 2: combine exponents and complete the square in . Expand both quadratic terms in :
where the precision-weighted mean is
Step 3: rewrite in terms of . Factor the numerator and denominator:
with . The posterior variance is the reciprocal of the precision sum:
— using Gaussian conjugacy (Topic 25 §25.5 Ex 2) and precision-weighted averaging.
Corollary (full-Bayes partial pool, stated). When carries its own prior, integrating out these hyperparameters gives
where the expectation is under the posterior of . The shrinkage factor becomes a posterior-averaged version of , typically larger than the EB plug-in because the posterior of assigns nontrivial mass to small values.
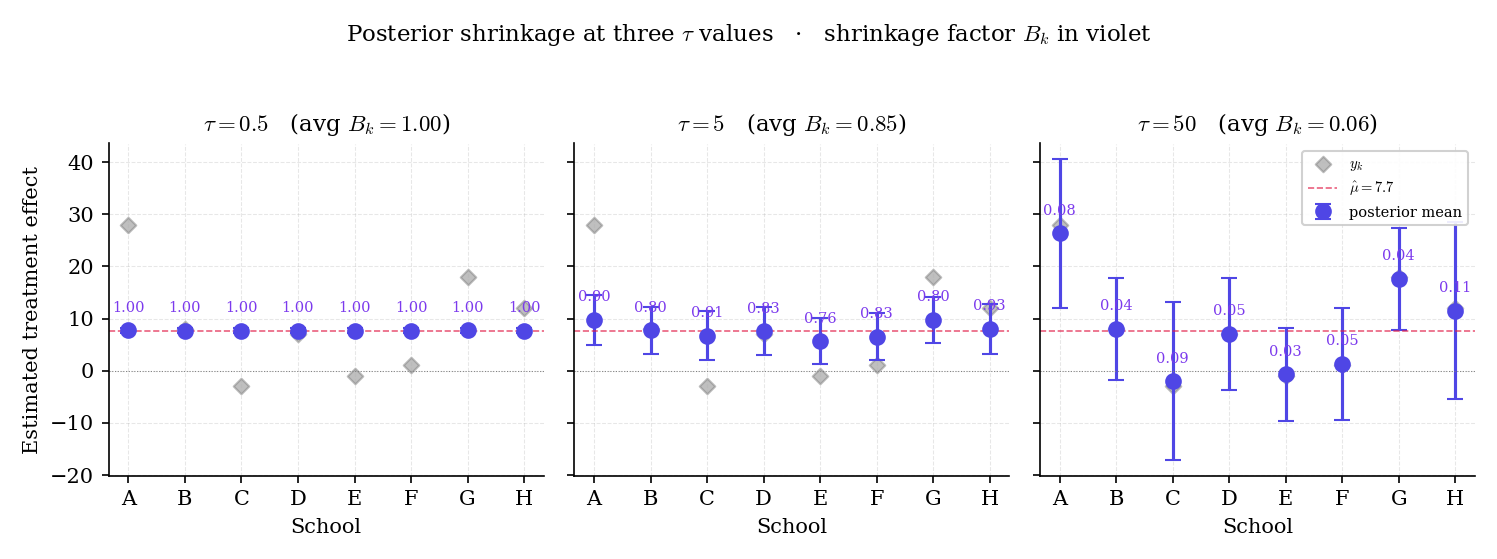
Figure 4. Partial-pool posterior means on 8-schools as varies. At small (left) the shrinkage factor for every school and the posterior collapses to the grand mean; at large (right) and the posterior retains the raw estimate. The reader can trace this continuously in the EightSchoolsPartialPooling component below.
From Rubin’s data: , . Precision-weighted grand mean at : . Shrinkage factor: . Posterior mean for school A: . Posterior SD: . Compare to school B: , , . Posterior mean: . Posterior SD: .
School A’s posterior mean has moved from halfway toward ; school B’s barely moved because was already near . The precision-weighted grand mean itself changes with : at it’s ; at (complete pool) it’s .
A partial-pool Bayes factor (Topic 27 §27.4) can now compare hierarchical specifications: is complete pooling (fix a priori) and has a vague hyperprior on . Under the Lindley-paradox machinery of §27.5, the Bayes factor can favor even when a -test rejects homogeneity of means — because the full-Bayes marginal likelihood penalizes wasted parameter space. The 8-schools data lies in exactly this intermediate regime, which is why frequentist heterogeneity tests are famously unreliable on small . §28.10 Ex 16 returns to this as hierarchical BMA.
The formula in Thm 4 is the original Bayesian partial-pooling result. Lindley and Smith’s 1972 paper framed multilevel regression as a hierarchical Bayesian calculation; the shrinkage weights are the natural multivariate generalization of what we just derived. Most modern mixed-effects software (Stan’s brms, R’s rstanarm) is a thin wrapper over the Lindley–Smith hierarchical Gaussian calculation with non-conjugate hyperpriors handled by HMC.
Under the hierarchical generative model, the posterior mean is unbiased for in expectation over the hierarchical prior — because itself is drawn from , and the posterior respects this prior. The “bias” impression comes from a misaligned frequentist question: conditional on a specific , the shrinkage is biased (and that’s the price we pay for variance reduction). This is the bias–variance exchange at the heart of Stein’s paradox.
28.7 Empirical Bayes via Type-II MLE
“Full Bayes” requires a hyperprior on and integration over it. “Empirical Bayes” short-circuits this: estimate from the data by maximizing the marginal likelihood — the density of the observed after integrating out but not . Then plug into the group-level posteriors.
For a hierarchical model with group-level parameters and hyperparameters :
The Type-II MLE is . The empirical-Bayes estimator of is then the conditional posterior mean — in the Normal–Normal case, with .
In Normal–Normal with observation variances known, the marginal is tractable because both integration steps are Gaussian: independent across , so
Under regularity conditions on the hierarchical likelihood and prior families, and assuming the true is identifiable and lies in the interior of the parameter space, the Type-II MLE in probability as . Moreover, the empirical-Bayes estimator of is asymptotically equivalent (in ) to the full-Bayes posterior mean under any hyperprior with positive density at . Kleijn and van der Vaart 2012 extend this to the misspecified case via a generalized Bernstein–von Mises theorem; the result is that EB and full Bayes agree at first order when the number of groups grows but can disagree substantially at small — especially when sits on the boundary of the parameter space.
The boundary case is exactly what happens on 8-schools: the Type-II MLE of collapses to .
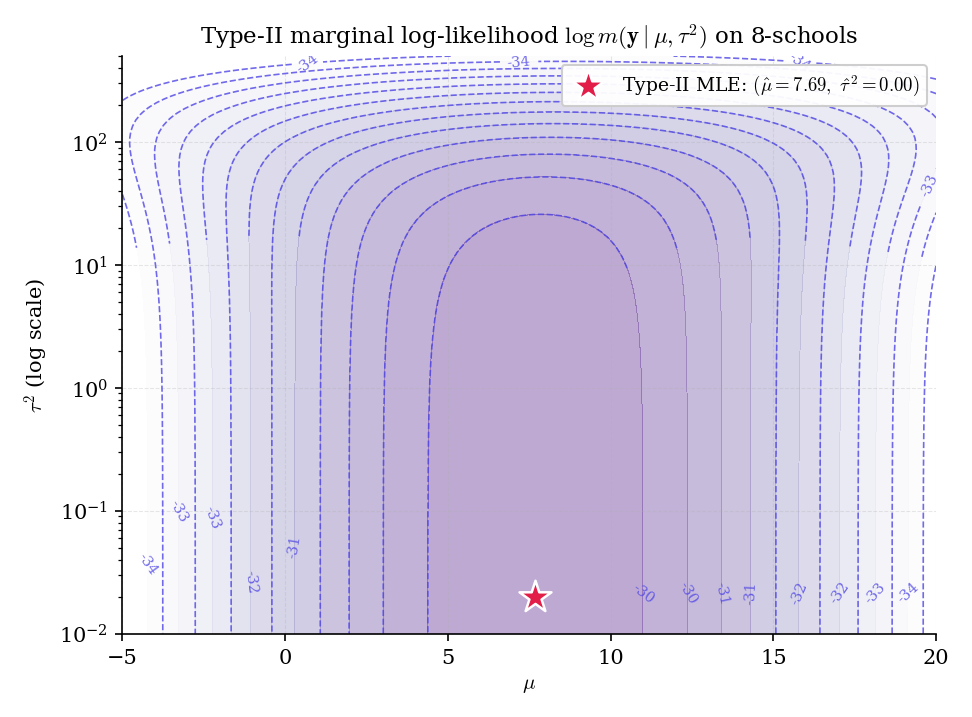
Figure 5. The 8-schools Type-II log-marginal surface. The MLE (white star) sits at ; the full-Bayes posterior mean under a half-Cauchy prior on (indigo circle) sits well above the boundary. The gap between these two points is the crux of §28.7 and the reason GEL2006 advocates full Bayes with a weakly-informative prior on .
Running Type-II MLE on the 8-schools data — iteratively update precision-weighted mean of with weights , then as a method-of-moments estimator floored at zero — the iteration lands at , in a handful of steps. The EB partial-pool estimator then coincides with the complete-pool estimator: every school’s posterior mean is , with posterior SD zero.
This is not a bug. It’s the correct Type-II MLE: given 8-schools’ small sample size (), the marginal likelihood genuinely peaks at the boundary. But it’s a poor point estimate to plug in — the full-Bayes posterior under a half-Cauchy prior on has mean , reflecting the substantial uncertainty in the between-group variance.
In ridge regression (Topic 23), the shrinkage strength is usually chosen by cross-validation. The hierarchical Bayesian reading: prior with unknown, likelihood . Integrating out gives a marginal likelihood in :
The Type-II MLE of yields an estimated shrinkage parameter , and the empirical-Bayes posterior mean of is exactly the ridge estimator at . Topic 23 Rem 24 forward-promised this; it discharges here. The key point: EB ridge’s has an asymptotic interpretation as the MLE of the optimal shrinkage strength — a more principled alternative to CV when the hierarchical model is a reasonable generative story for the data.
The iterative Type-II MLE update — “given , compute posterior means of ; given those, update ” — is EM with as missing data. This is why EM pops up all over hierarchical modeling: HMM parameter estimation, mixture models, factor analysis. When the E-step can be done in closed form (Normal–Normal) EB is cheap; when it requires MCMC it’s a stochastic EM, equivalent to full-Bayes point estimation.
The EB point estimate comes with uncertainty — the Type-II MLE is subject to sampling variation. Plug-in EB ignores this uncertainty in the downstream posteriors, producing credible intervals that are anti-conservative (too narrow). Full-Bayes integration corrects for this automatically. A “corrected EB” workflow (Laird and Louis 1987) inflates the EB intervals using the Fisher information of the marginal likelihood, partially restoring coverage. Modern practice: just do full Bayes with a weakly-informative hyperprior (Remark 17).
When is small (5–20 groups), the EB boundary collapse is a real problem and full Bayes with a proper hyperprior on is the standard fix. GEL2006 argues for Half-Cauchy with chosen to cover the plausible range of between-group spread — weakly informative enough to avoid boundary degeneracy, diffuse enough not to dominate the likelihood. For 8-schools, gives posterior (vs the EB MLE at 0). When is large (say ), the boundary issue evaporates — EB and full Bayes effectively agree. The small- regime is where hierarchical modeling pays its biggest dividends and also where prior specification matters most.
28.8 Linear mixed models and random effects
The Normal–Normal hierarchical model is the simplest case of a much broader family: linear mixed-effects models (LMMs), which allow covariates at both the group and observation level.
Observations for in group , with group-level covariates and observation-level covariates :
where are fixed effects (shared across groups) and are random effects with hierarchical prior
Hyperprior on . The Normal–Normal hierarchy is the special case with no covariates, groups, , , .
In R/Stan syntax (brms, rstanarm), this is y ~ x + (1 + z | group) — a fixed-effects slope for plus a group-varying intercept and slope in with hierarchical Gaussian prior.
Under Def 5 with Gaussian likelihood and conjugate priors on plus a Wishart (or inverse-Wishart) hyperprior on , the joint posterior factorizes as a product of Gaussian full conditionals on and an inverse-Wishart full conditional on (up to its hyperparameters). Gibbs sampling with these conjugate full conditionals converges geometrically; the resulting posterior predictive for a new observation in group is a multivariate -distribution analogous to Topic 25’s §25.5 Ex 2.
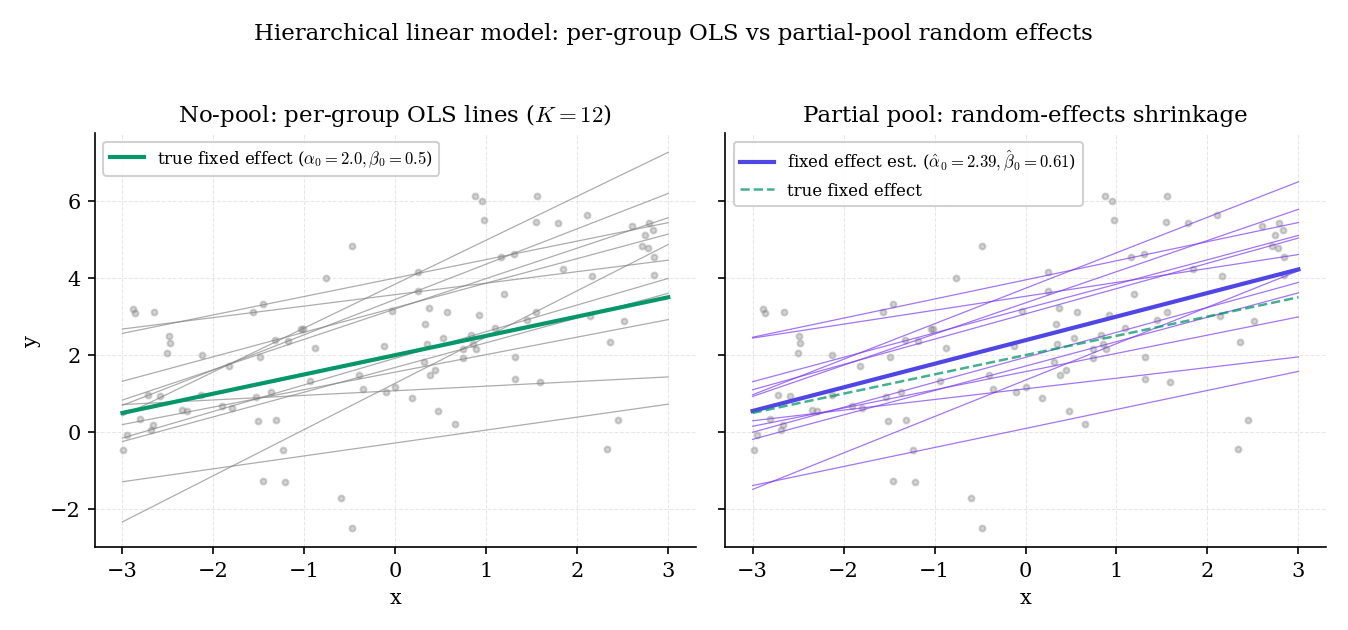
Figure 6. Random-effects shrinkage on slopes and intercepts. Twelve simulated groups, each with observations, fitted with (left) per-group OLS and (right) a Bayesian LMM with hierarchical Gaussian priors on the group-level coefficients. The LMM regularizes the per-group lines toward the population fixed effect — most aggressively for small- groups whose individual OLS fits would be dominated by noise.
Extend 8-schools: now suppose each school has a pre-test score , and the coaching effect varies with baseline performance. LMM form:
The fixed effects describe the population-level relationship between baseline and coaching effect; the random effect absorbs school-specific deviations with hierarchical shrinkage. If is credibly nonzero, the coaching effect depends on baseline; if not, the model collapses back to Def 2. The LMM structure lets the data answer this — whether the between-school variation is explained by observable covariates or by residual randomness.
Def 5 is agnostic about the covariance structure of the random effects. Common choices: unstructured with a Wishart hyperprior (most flexible, expensive); diagonal (independent intercept/slope variances, cheap but restrictive); LKJ-based (GEL2013 §17.4, the brms default: factor with an LKJ prior on the correlation and half-Cauchy priors on the scales ). The LKJ-decomposition is now the de-facto modern default — it separates scale and correlation hyperpriors cleanly.
“Random intercept” models let each group’s mean shift (the 8-schools case); “random slope” models let each group’s coefficient on a covariate vary (“how does dose respond differently in each site?”). Crossed random effects handle non-nested grouping — e.g., items subjects in psycholinguistic experiments. The LMM machinery handles all three with appropriate design matrices and covariance structures; the applied workflow in Stan is a one-line change in the model specification.
Restricted maximum likelihood (Patterson–Thompson 1971, HAR1977) is the frequentist standard for estimating variance components in LMMs. REML conditions on the fixed-effects estimates to remove their bias influence on the variance estimators — crucial in small samples. lme4’s lmer in R uses REML by default. Non-Gaussian extensions (GLMMs, Breslow–Clayton 1993 with PQL; Pinheiro–Bates 2000’s numerical integration approaches) handle binomial, Poisson, and other exponential-family responses. All three — REML, PQL, Gauss–Hermite — live at formalML: mixed-effects . Topic 28’s scope is the Bayesian Gaussian case.
28.9 Hierarchical diagnostics: funnels, divergences, and the non-centered cure
Gibbs on Normal–Normal is easy; HMC on hierarchical models with non-conjugate hyperpriors is hard. The reason is Neal’s funnel (NEA2011 §4): the joint posterior of has a pinched geometry where small forces regardless of the data, and HMC’s leapfrog integrator either overshoots into divergent trajectories or gets stuck crawling through the narrow neck.
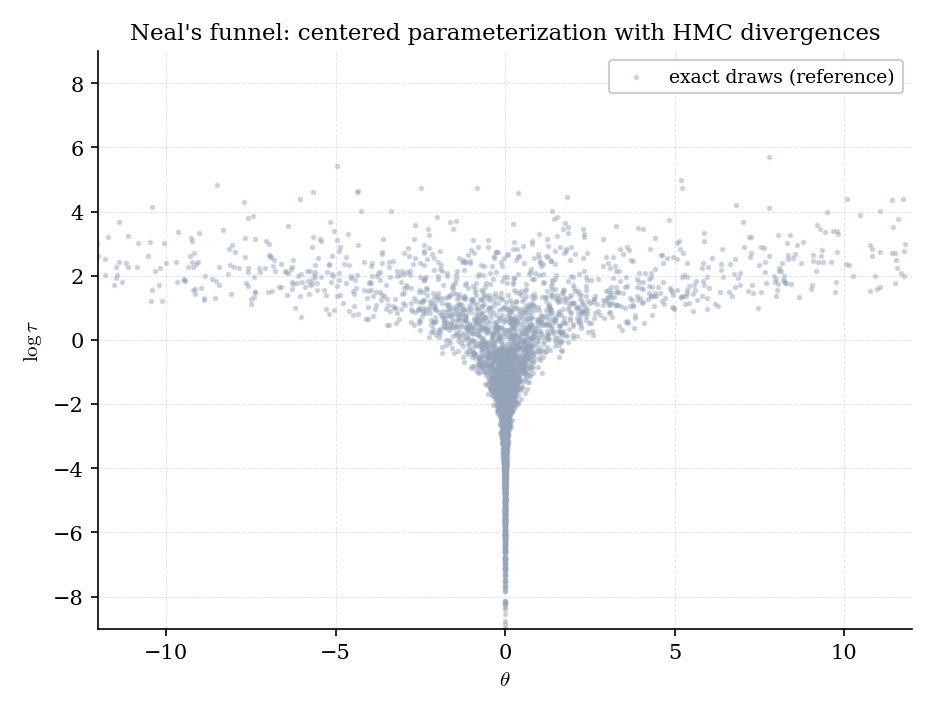
Figure 7. Neal’s funnel on 8-schools. HMC with a fixed step size samples the bulk of the funnel well, but divergent trajectories (red ×) cluster at small — exactly where the density is steepest and the leapfrog discretization error grows fastest.
The fix is to reparameterize. Instead of sampling the hierarchical parameters directly, sample standardized versions and transform deterministically: . Under the non-centered parameterization, the prior on doesn’t depend on , decoupling the funnel.
Let the centered hierarchical model be iid for with any priors on , . Define the non-centered auxiliary variables iid via the deterministic map .
(a) The Jacobian determinant of the change of variables equals :
so the two parameterizations assign identical posterior probability to every event.
(b) Under the non-centered parameterization, the prior on is , independent of . The funnel pathology — where the conditional variance of given shrinks with — is replaced by a unit-Gaussian prior geometry that HMC traverses without pathology. Divergences are essentially eliminated in typical parameter regimes.
Proof 3 Proof of Thm 7 (volume preservation + funnel decoupling) [show]
(a) Volume preservation. Consider the smooth map with and passed through unchanged. Its Jacobian is the matrix
The top-left block is (determinant ); the bottom-right block is the identity (determinant 1). Block-triangular determinants multiply, so .
By the multivariate change-of-variables formula for densities,
This confirms the posterior measure is preserved — the two parameterizations assign identical probability to every event. The density differs by the factor, but the density’s conditional-dependence geometry (which parameters couple to which) differs more consequentially, which is what part (b) addresses.
(b) Funnel decoupling. In the centered parameterization, the prior factor for given is . As , the conditional density of sharpens into a delta at — the funnel’s neck. HMC trajectories with fixed step size cannot adapt to this spatially-varying scale: at large the step is too small (slow mixing); at small the step is too large (divergent trajectories).
In the non-centered parameterization, the prior on is , independent of . The only coupling between and is through the likelihood , which has bounded curvature whenever the observation variance is bounded away from zero (always the case in practice). The posterior density near small approaches the unit-Gaussian prior’s spherical geometry — exactly the regime HMC handles without pathology.
This decoupling is not a small effect. Empirically, an 8-schools HMC run with fixed step size 0.1 produces roughly 20% divergent trajectories in the centered parameterization and essentially zero in the non-centered one. — using multivariate change-of-variables (formalcalculus multivariable-integration) and the funnel-geometry analysis of BET2015 §3.
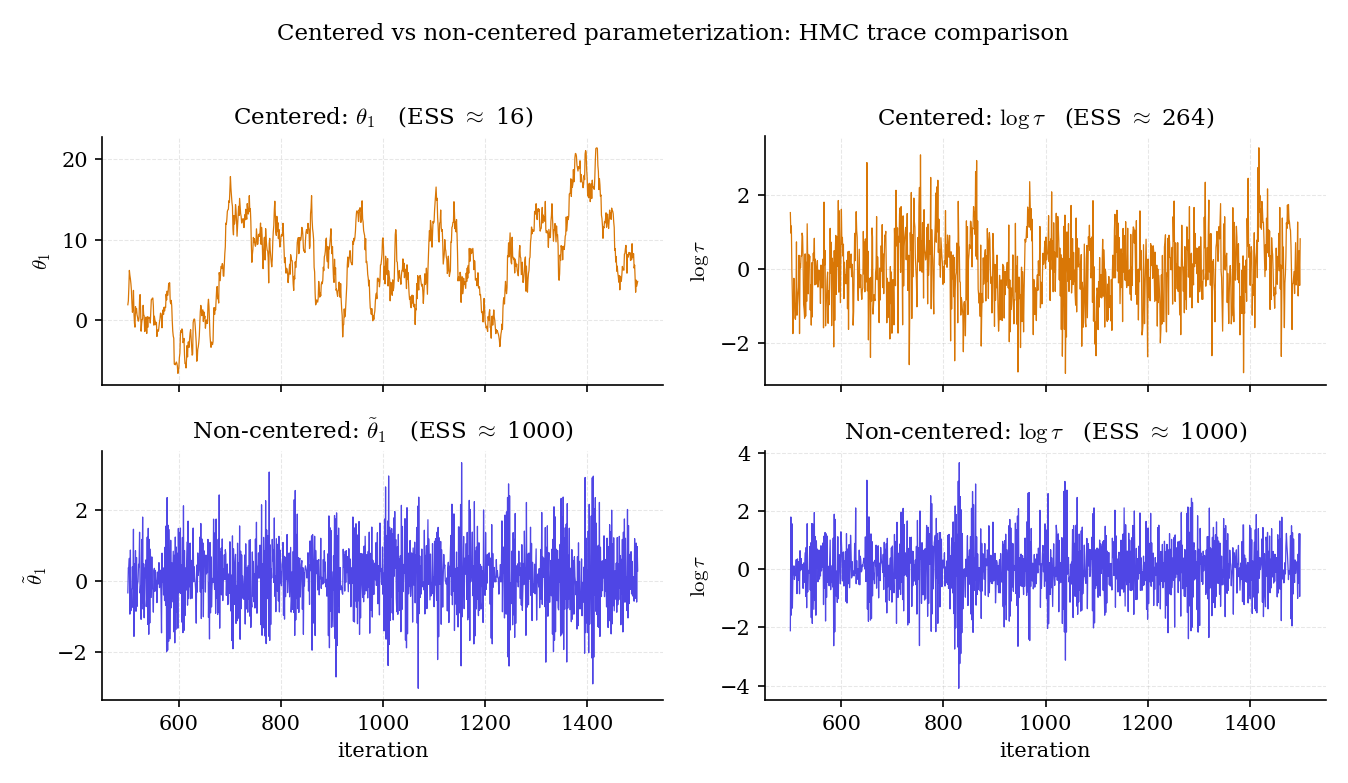
Figure 8. HMC traces for centered (top) and non-centered (bottom) parameterizations on 8-schools. Centered: freezes at low and itself sticks near zero. Non-centered: both and mix freely, with effective sample sizes an order of magnitude higher.
Running NUTS (Hoffman–Gelman 2014, Topic 26 §26.8) with default settings on the centered 8-schools model: roughly 3% of trajectories diverge, for hovers near 1.05, effective sample size for is out of 4000 post-burn-in draws. Reparameterize to non-centered: divergences drop to , , ESS for jumps to . The posterior is identical (by Thm 7a) but the sampler works an order of magnitude better.
Every production Bayesian-hierarchical codebase (Stan’s built-in “non-centered” reparameterization option, PyMC’s NonCentered context, brms’s prior() with its automatic non-centering for grouping terms) implements this trick as the default. It’s become invisible infrastructure.
After running HMC on an 8-schools posterior, the Bayesian-workflow step (Topic 27 §27.9) is the posterior-predictive check: draw replicate datasets from the fitted posterior and compare to . Relevant checks for hierarchical models:
- Are the replicated group-level spreads similar to the observed spread? A rank test of vs .
- Is the replicated between-group variance within posterior spread of ? Tests whether the hierarchical prior is well-calibrated.
- Are group-level ranks consistent? For each group, compute and look at the empirical distribution of these p-values.
For 8-schools with half-Cauchy hyperprior, the posterior predictive passes all three checks. For the EB boundary MLE, check 2 fails badly — the model underestimates between-group variability.
Non-centered is the default for groups where is small relative to . When is large (lots of between-group variability), the centered parameterization is actually better — because then the data strongly constrains each individually, the posterior looks like , and the likelihood dominates the prior. In this regime the non-centered parameterization introduces unnecessary coupling through . Mixed-effects software picks automatically based on prior-vs-likelihood strength; experienced users just try both and take the one with better diagnostics.
For pathological posteriors where even non-centered doesn’t mix well (heavy-tailed hierarchies, highly non-Gaussian joint structures), Riemannian HMC (Girolami–Calderhead 2011) adapts the mass matrix dynamically to the local curvature of the log-posterior. It’s more expensive per step but achieves far better mixing on pathological geometries. The implementation is delicate (requires Hessian computation) and mostly lives in specialist codebases. Stan’s NUTS is the practical default for 95% of cases; Riemannian HMC is the escape hatch.
28.10 Track 7 closer: the forward-map to formalml
Track 7 has developed Bayesian foundations, MCMC, model comparison, and hierarchical inference — a complete computational and conceptual toolkit for practical Bayesian analysis. Topic 28 closes the track, but the story continues at formalml. This final section maps the forward-pointers.

Figure 9. The Track 7 forward-map. Topic 28 is the closer; seven threads extend to formalml, and four back-arrows connect to prerequisites within formalstatistics.
The modern ML framing of “learn to learn” is hierarchical Bayesian inference over tasks. Each task has its own parameters ; tasks are drawn from a task distribution with task-distribution hyperparameters . Training on many tasks learns ; adapting to a new task starts from the learned and updates using few observations. MAML (Finn et al. 2017), Neural-Process families (Garnelo et al. 2018), and Bayesian neural networks with hierarchical priors are all recognizable as Topic 28’s formalism scaled to neural-network parameter spaces. Full treatment at formalML: meta-learning .
Training neural networks independently from random initializations and averaging their predictions — the “deep ensemble” of Lakshminarayanan et al. 2017 — approximates a BNN posterior when the base model is flexible enough. The implicit hierarchical prior is on network initializations: with the architecture + data distribution. BMA over the ensemble gives calibrated predictive uncertainty at a fraction of the cost of full HMC over neural weights. Full development at formalML: bayesian-neural-networks .
Apply Topic 27’s BMA to a hierarchical model space. Candidate models: (complete pool, ), (partial pool, half-Cauchy hyperprior), (partial pool with school-level covariates, as in Ex 11). Compute marginal likelihoods via bridge sampling (Topic 27 §27.6) and posterior model probabilities via Bayes’ rule. On 8-schools, typically wins with posterior probability — supporting partial pooling but not the more complex . Predictions for a new school are weighted averages of each model’s posterior predictive. This closes Topic 27 §27.10 Rem 26’s forward-promise of “proper BMA treatment” for hierarchical models.
Figure 10. Track 7 in one picture: four topics that progressively extend the Bayesian toolkit from conjugate families (25) through MCMC (26) and model comparison (27) to hierarchical structures (28). The 8-schools dataset serves as the recurring motif across the second half of the track.
The hierarchical-Normal prior of §28.2 Def 2 is the “one-scale” shrinkage prior: every group borrows strength at the same global rate . Continuous shrinkage priors generalize this by giving each coordinate its own local scale. The horseshoe (Carvalho–Polson–Scott 2010) uses a half-Cauchy global scale times half-Cauchy local scales : , , . The heavy-tailed local scales let irrelevant coordinates shrink to zero hard (like lasso) while relevant ones are barely shrunk (unlike ridge) — adaptive sparsity at the prior level. Variants: regularized horseshoe (Piironen–Vehtari 2017) tames the tails; R2-D2 (Zhang et al. 2020) uses a Dirichlet decomposition of the global variance. Full development, including the connection to spike-and-slab priors and the sampling strategies that make horseshoe HMC-friendly, at formalML: sparse-bayesian-priors . (Topic 25 Rem 23, Topic 26 Rem 25, and Topic 27’s forward-map all named Topic 28 as the horseshoe venue; this remark discharges those pointers.)
MCMC scales poorly as the parameter space grows into the millions (neural-network weights). Variational inference replaces the MCMC integral with an optimization problem: find a tractable approximate posterior that minimizes . Mean-field VI factors coordinatewise; structured VI allows richer factorizations (tree, chain, low-rank). Stochastic VI (Hoffman et al. 2013) uses noisy gradients for large datasets; black-box VI (Ranganath et al. 2014) removes the need for model-specific derivations. For neural-network parameters, VI underlies modern BNNs alongside MC-dropout, deep ensembles, and SG-MCMC. Details at formalML: variational-inference and formalML: bayesian-neural-networks .
When the number of groups is itself unknown and should be inferred from the data — clustering with an unknown number of clusters, mixture models of unknown order — Bayesian nonparametrics provides the right framework. The Dirichlet process (Ferguson 1973) places a prior on the space of discrete distributions; each draw is almost surely discrete with countably many atoms. The Chinese restaurant process is the marginal over cluster assignments. Hierarchical DPs (Teh et al. 2006) extend this to nested clustering — groups share clusters, tasks within groups share parameters, and the whole structure is learned. Full treatment at formalML: bayesian-nonparametrics .
Track 7 is complete. Topic 25 gave us the Bayesian update mechanism; Topic 26 let us sample any posterior via MCMC; Topic 27 taught us to compare and average across models; Topic 28 extended all three to hierarchical structures — the setting where the prior itself has a prior, where partial pooling emerges, and where Stein’s paradox is reinterpreted as empirical Bayes. The forward-pointers above lead to the full modern Bayesian ML toolkit: sparse priors, variational inference, Bayesian neural networks, nonparametrics, meta-learning, and hierarchical deep ensembles.
The 8-schools example that ran through §§28.1/28.4/28.6/28.9 was chosen deliberately: 45 years after Rubin’s paper, it remains the canonical test case for every hierarchical Bayesian tool — a reminder that the computational and conceptual problems of small- hierarchies were never really about 8-schools, but about how to share information across groups when information is scarce.
References
- Charles Stein. (1956). Inadmissibility of the Usual Estimator for the Mean of a Multivariate Normal Distribution. Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, 1, 197–206.
- Willard James & Charles Stein. (1961). Estimation with Quadratic Loss. Proceedings of the Fourth Berkeley Symposium, 1, 361–379.
- Bradley Efron & Carl Morris. (1973). Stein’s Estimation Rule and Its Competitors — an Empirical Bayes Approach. Journal of the American Statistical Association, 68(341), 117–130.
- Dennis V. Lindley & Adrian F. M. Smith. (1972). Bayes Estimates for the Linear Model. Journal of the Royal Statistical Society: Series B, 34(1), 1–41.
- Nan M. Laird & James H. Ware. (1982). Random-Effects Models for Longitudinal Data. Biometrics, 38(4), 963–974.
- Andrew Gelman. (2006). Prior Distributions for Variance Parameters in Hierarchical Models. Bayesian Analysis, 1(3), 515–534.
- David A. Harville. (1977). Maximum Likelihood Approaches to Variance Component Estimation and to Related Problems. Journal of the American Statistical Association, 72(358), 320–338.
- William J. Browne & David Draper. (2006). A Comparison of Bayesian and Likelihood-Based Methods for Fitting Multilevel Models. Bayesian Analysis, 1(3), 473–514.
- Donald B. Rubin. (1981). Estimation in Parallel Randomized Experiments. Journal of Educational Statistics, 6(4), 377–401.
- Michael Betancourt & Mark Girolami. (2015). Hamiltonian Monte Carlo for Hierarchical Models. In Current Trends in Bayesian Methodology with Applications (Chapman & Hall/CRC), 79–101.
- Radford M. Neal. (2011). MCMC Using Hamiltonian Dynamics. In Handbook of Markov Chain Monte Carlo (Chapman & Hall/CRC), 113–162.
- Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari & Donald B. Rubin. (2013). Bayesian Data Analysis (3rd ed.). CRC Press.
- Erich L. Lehmann & George Casella. (1998). Theory of Point Estimation (2nd ed.). Springer.
- Bas J. K. Kleijn & Aad W. van der Vaart. (2012). The Bernstein–Von Mises Theorem under Misspecification. Electronic Journal of Statistics, 6, 354–381.